1. 데이터베이스의 등장 배경
1) 파일시스템
: 데이터를 파일로 관리하기 위해 파일을 생성·삭제·수정·검색하는 기능을 제공하는
OS 속 소프트웨어이다. 응용 프로그램마다 필요한 데이터를 별도의 파일로 관리한다.
- 파일 시스템의 문제점
사용하는 파일의 구조를 변경하면 관련된 모든 응용프로그램에서 파일에 접근하는 방법을 변경해야했다.
응용 프로그램마다 데이터를 별도의 파일로 관리하기 때문에 사용자들 간 정보 공유가 되지 않는 문제와
이로인한 데이터 중복성 문제도 있었다.
2) 데이터베이스 관리 시스템
※ 용어 정리
- SQL 언어: 현재 가장 널리 사용되는 데이터베이스 언어로
2. 데이터베이스 시스템 발전 과정
| 1960년대 초반 | 최초의 데이터베이스 IDS(Integrated Data Store) |
| 1960년대 후반 | IBM사에서 IMS(Information Management System)개발 |
| 1970년 6월 | IBM연구소의 Codd박사 관계형 데이터 모델 제시 |
| 1970년대 초반 | System/R, 최초의 관계형 데이터베이스 시스템 모델 개발 |
| 1979년 | 오라클 V1, 최초의 상용 관계형 데이터베이스 시스템 출시 |
| 1982년 | SQL/DS, IBM의 상용 관계형 데이터베이스 제품 출시 |
| 현재 | 오라클, DB2, Sybase, SQL Server 사용 중 |
3. SQL의 역사
| 1973 | SQUARE(Structured Queries As Relational Express) |
| 1974 | System/R용 SEQUEL(Structured English QUEry Language) |
| 1976 | SEQUEL-2 |
| 1980 | SQL(Structured Query Language)로 개명 |
| 1986 | SQL-86, 최초의 SQL 표준안 |
| 1988 | ANSI, ISO 국제표준 인정 |
| 1989 | SQL-1(SQL/89) 표준안 제정 |
| 1992 | SQL-2(SQL/92) 표준안 제정 |
| 1999 | SQL-3(SQL/99) 표준안 제정 |
4. 객체지향 데이터베이스 & 객체관계형 데이터베이스
1) 객체지향 데이터베이스 시스템
- O2, Versant, Ontos, ObjectStore, Objectivity 등
2)객체관계형 데이터베이스 시스템
5. 데이터베이스 정의와 특징
1) 데이터베이스 정의
- 통합 데이터(integrated data)
- 공유 데이터(shared data)
- 저장 데이터(stored data)
- 운영 데이터(operational data)
- 의사결정 데이터(decision-making data)
2) 데이터베이스 특징
- 실시간 접근(realtime access)
- 지속적인 변화(continuous changes)
- 동시 공유(concurrent sharing)
- 내용에 의한 참조(reference by content)
6. 관계형 데이터 모델

관계형 데이터 모델은 데이터구조(릴레이션), 관계연산(집합 연산, 관계 연산)과 제약조건(무결성 규칙)으로
이루어져있다고 볼 수 있다.
7. 릴레이션
1) 릴레이션(relation)이란
튜플(tuple)과 속성(attribute)의 집합으로 구성된 2차원 테이블 구조이다.
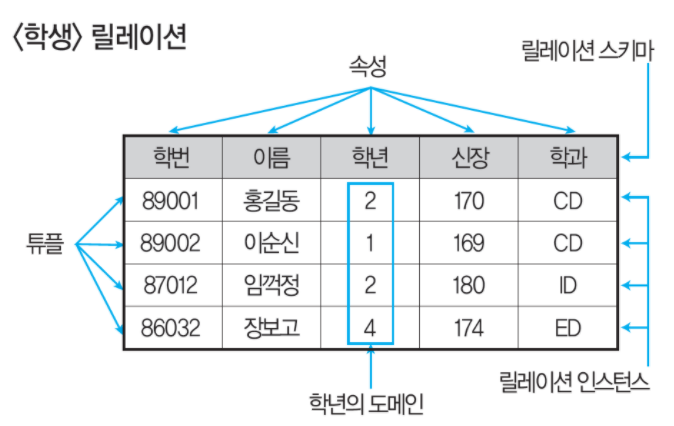
2) 릴레이션의 성질
- 릴레이션에 저장된 튜플들은 유일하다.
- 릴레이션에 저장된 튜플 간에는 순서 관계가 없다.
- 릴레이션을 구성하는 속성간에는 순서가 없다.
- 모든 속성 값은 원자 값(atomic value)이다.
8. 관계 연산과 SQL
| UNION : 합집합 | 예 : SELECT a FROM R UNION SELECT b FROM S; |
| INTERSECT : 교집합 | 예 : SELECT a FROM R INTERSECT SELECT b FROM S; |
| DIFFERENCE : 차집합 | 예 : SELECT a FROM R MINUS SELECT b FROM S; |
| PRODUCT : 카티션 곱 | 예 : SELECT a, b FROM R, S; |
| RESTRICTION : 수평적인 부분 집합 | 예 : SELECT * FROM R WHERE r.A=10; |
| PROJECTION : 수직적인 부분 집합 | 예 : SELECT r.A1, r.A2 FROM R; |
| JOIN | 예 : SELECT r.A, r.B FROM R, S WHERE r.A = s.B; |
9. 제약 조건
1) 엔터티 무결성 규칙
- 기본 키(primary key)
2) 참조 무결성 규칙
: 릴레이션간의 데이터의 일관성을 보장하기 위한 제약조건이다.
참조되는 속성 값이 반드시 해당 릴레이션에 존재해야 한다.
* 참조 키(reference key) : 다른 릴레이션에서 참조되는 칼럼
3) 도메인 무결성 규칙
10. 데이터베이스 관리시스템
1) 데이터베이스 관리시스템이란
: Database Management System,
2) 주요 기능
| 데이터 정의 기능 |
- 데이터베이스에 스키마를 정의한다.
- 테이블, 인덱스, 동의어, 시퀀스 등과 같은 스키마 객체(schema object)를 생성, 변경, 삭제할 수 있다.
- CREATE TABLE, ALTER TABLE, DROP TABLE, CREATE INDEX등
|
| 데이터 조작 기능 |
- 테이블이나 뷰와 같은 스키마 객체에 저장된 데이터를 조작하는 기능이다.
- 새로운 데이타를 입력, 수정 또는 삭제할 수 있다.
- INSERT, UPDATE, DELETE문
|
| 데이터 제어 기능 |
- 데이터의 정확성과 안전성을 유지하기 위한 기능이다.
- 데이터의 정확성 유지를 위한 트랜잭션 관리나 접근 권한을 관리할 수 있다.
- COMMIT, ROLLBACK, GRANT, REVOKE등
|
3) 장점
| 데이터 중복의 최소화 | - 데이터의 통합 관리를 통하여 데이터의 중복을 최소한으로 줄일 수 있음 |
| 데이터의 공유 | - 데이터의 통합 관리를 통하여 여러 사용자가 동일한 데이터를 공유 가능 |
| 데이터의 일관성 유지 | - 통합된 데이터의 체계적인 관리를 통하여 데이터의 일관성을 유지 |
| 데이터의 무결성 유지 | - 무결성 규칙에 의해 데이터에 대한 정확성과 일관성을 유지 |
| 데이터의 보안 보장 | - 데이터에 대한 중앙집중 관리를 통하여 사용자의 접근을 효율적으로 통제 |
| 전체 데이터에 대한 요구 조정 | - 데이터에 대한 액세스 빈도, 변경 주기, 저장 공간 관리와 사용자 요구 사항을 파악하여 전체 데이터에 대한 요구 조건을 조정 |
4) 단점
| 운영비 증대 | - 데이터베이스 관리시스템 운영을 위한 하드웨어, 소프트웨어 및 인력 운영 비용이 증가함 |
| 자료 처리의 복잡화 | - 일관성과 보안을 유지하며 데이터를 통합 관리하기 위해 시스템 내부적인 자료 처리가 복잡함 |
| 복잡한 예비작업과 회복 |
- 데이터베이스는 통합된 데이타를 여러 사용자가 동시에 사용하는 관계로
장애 발생시에 복구 과정이 복잡함 - 안정적인 복구를 위해 적절한 백업 작업이 필요함
|
| 시스템의 취약성 | - 데이터에 대한 의존도가 높은 조직이나 업무는 장애 발생시 시스템에 대한 신뢰성과 가용성을 저하될 수 있음 |
'SQL' 카테고리의 다른 글
| #5. 집합 연산자와 행의 정렬 (0) | 2022.04.12 |
|---|---|
| #4. 조건 검색 (0) | 2022.04.12 |
| #3. 데이터 타입(ORACLE) (0) | 2022.04.11 |
| #2. SQL 언어 (0) | 2022.04.10 |



